Here's a cool little workflow that I use to automate the usage of images in my posts1
The flow
- Move the image I would like to use to my
black-holefolder - When a new file is added to the folder, or existing file is modified, a Hazel is triggered
- This Hazel rule fires up a python script
- The python script:
- Pushes updates to my Amazon S3
- Returns a link to the uploaded file
- Place the link in the clipboard
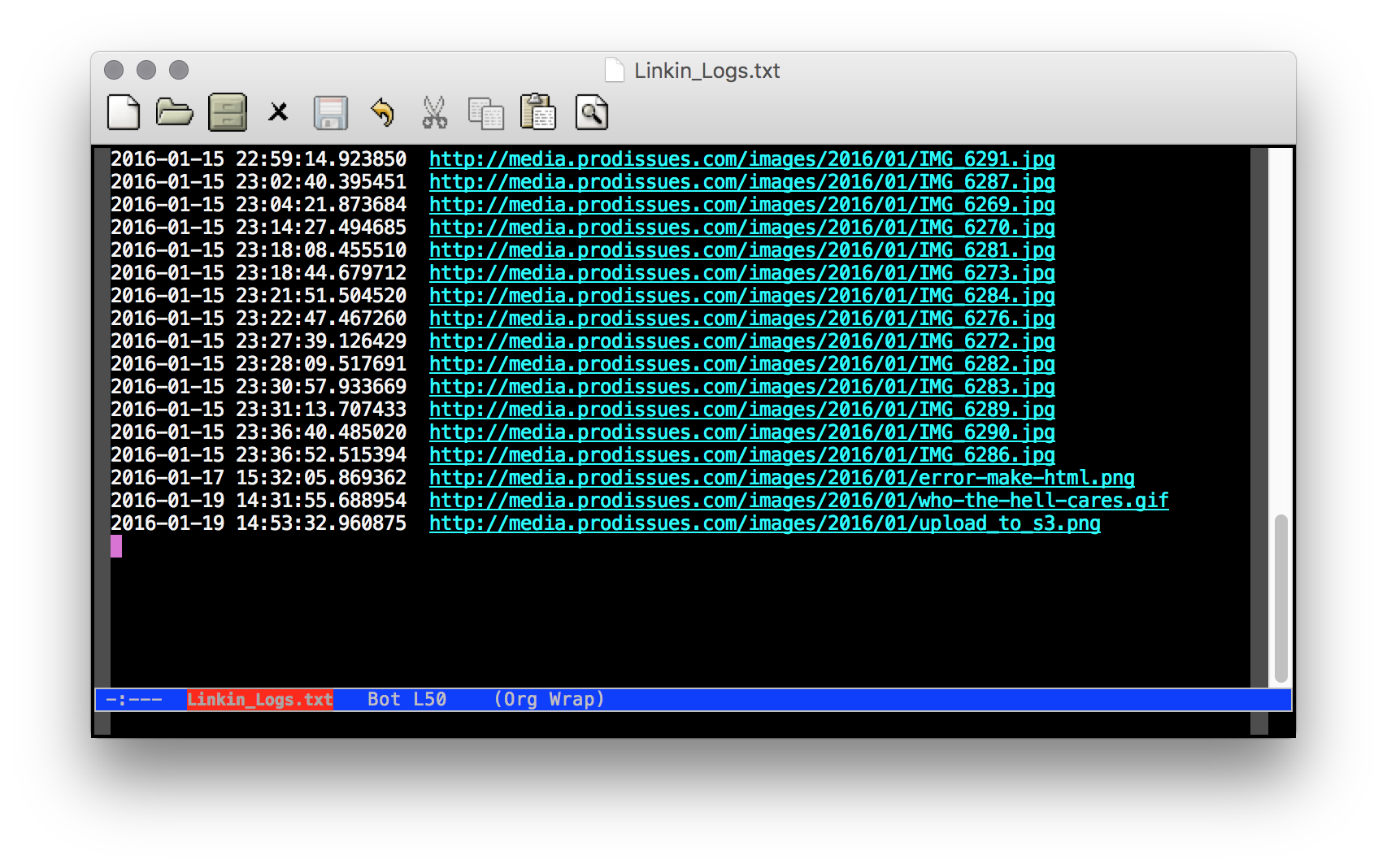
- Add a log entry that includes the timestemp and the link to that file
The Porcelain
Here's how the flow in action:
The Plumbing
And here are the ingredients in more detail:
The Hazel rule
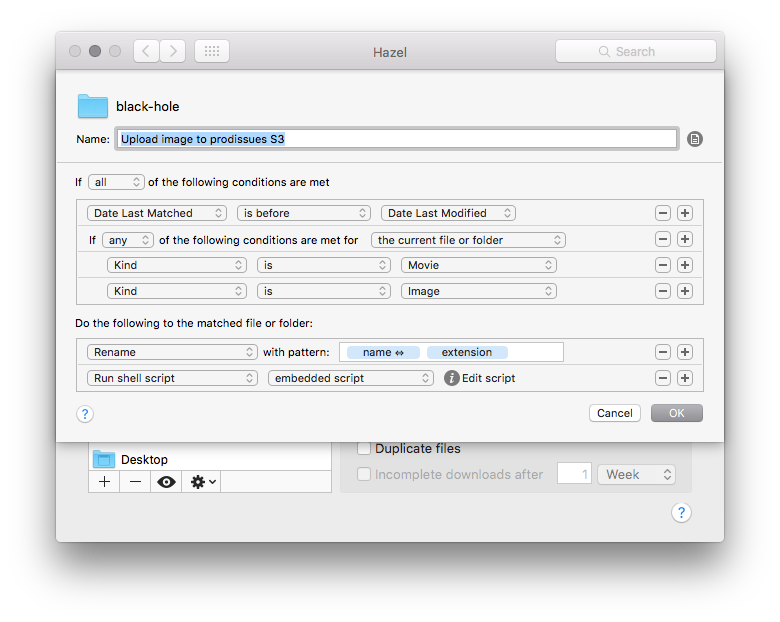
Figure 1: Note that I rename the
filename, such that spaces replaced by _. Otherwise the upload to S3
doesn't work
The python script
#+BLOG: yanivgilad
#+POSTID: 57
#+DATE: [2016-01-19 Tue 20:42]
# Source: https://github.com/yanivdll/python-scripts/blob/master/s3_upload.py
# This script upload files (at the moment images and slideshows) to S3.
#
# Credits:
# This script is inspired by macdrifter script, which can be found at:
# http://www.macdrifter.com/2012/05/upload-to-amazon-s3-from-dropbox-using-hazel.html
import boto
from boto.s3.connection import S3Connection
import pyperclip
import os
import sys
from datetime import date, datetime
# This is how Hazel passes in the file path
hazelFilePath = sys.argv[1]
contentType = sys.argv[2]
# This is where I store my log file for these links. It's a Dropbox file in my NVAlt notes folder
logFilePath = "~/Dropbox/Notes/Linkin_Logs.txt"
nowTime = str(datetime.now())
# This is the method that does all of the uploading and writing to the log file.
# The method is generic enough to work with any S3 bucket that is passed.
def uploadToS3(localFilePath, localFileType, S3Bucket):
fileName = os.path.basename(localFilePath)
# Determine the current month and year to create the upload path
today = date.today()
datePath = today.strftime("/%Y/%m/")
# Connect to S3
s3 = boto.connect_s3()
bucket = s3.get_bucket(S3Bucket)
# Set the folder name based on the content type image\slideshow
if localFileType == 'slideshow':
key = bucket.new_key('slideshows/' + fileName)
else:
key = bucket.new_key('images' + datePath + fileName)
# Upload file to S3
key.set_contents_from_filename(localFilePath)
key.set_acl('public-read')
# Log the url of the hosted file
logfile = open(logFilePath, "a")
# Create the URL for the image
imageLink = 'http://' + S3Bucket + '/' + key.name
try:
# encode the file name and append the URL to the log file
logfile.write(nowTime+' '+imageLink+'\n')
pyperclip.copy(imageLink)
finally:
logfile.close()
# The body of the script.
uploadToS3(hazelFilePath, contentType,'media.prodissues.com')
Few remarks about boto
- If you're new to boto, a python interface to Amazon AWS, read through this tutorial.
- Boto's credentials file lives in
~/.botofile. However, I found that when not running thes3_upload.pyfrom a python environment such as IDLE, but from a terminal, the credential file that is being used is the~/.aws/credentialsfile. So I just made sure that my AWS credentials exist in both files. - Since my bucket has dots in it (
media.prodissues.com) I had to define the S3 bucket format2 explicitly:
[default]
aws_access_key_id = [my_aws_access_key]
aws_secret_access_key = [my_aws_secret_access_key]
[s3]
calling_format = boto.s3.connection.OrdinaryCallingFormat
The log file
Summary
Setting this workflow might look more intimidating than it really is. But even if it is, the gratifing feeling of throwing a file into a folder and getting a live link in exchange is totally worth it.
-
Heavily inspiered by Macdrifter's "Upload to Amazon S3 from Dropbox using Hazel" ↩
-
See this thread for more details: https://github.com/boto/boto/issues/2836 ↩